Last Updated on September 19, 2025
Internal linking is a crucial aspect of search engine optimization (SEO). It not only helps search engines understand the structure and content of your website but also improves user navigation and engagement. While external links are essential, internal links play a significant role in enhancing your website’s SEO performance. In this blog, we will explore how you can use Python to find contextual internal links on your website, allowing you to optimize your internal linking strategy effectively.
- Why internal linking is so vital for SEO ?
- Preparing Your Python Environment
- Defining the Target Website
- Skipping Unwanted URL Patterns
- Crawling the Website
- Filtering mechanism for Contextual Links
- Handling Interrupts and Errors
- Signal handler for interrupt signal (Ctrl+C)
- Python code
- Generating Reports and Visualizations
- Best Practices for Internal Link Optimization
- Conclusion
Why internal linking is so vital for SEO ?
Before we dive into the technical details of using Python for internal link analysis, let’s understand why internal linking is so vital for SEO. Internal links are links that point from one page on your website to another page within the same domain. They serve several critical purposes:
- Improved Crawling and Indexing: Search engines like Google use web crawlers to index web pages. Internal links help these crawlers discover and navigate through your site’s content more efficiently.
- Enhanced User Experience: Internal links provide a smooth and logical navigation path for users. They can easily move from one related topic to another, increasing user engagement.
- Keyword Relevance: Internal links allow you to use keywords in anchor text, which signals the topic or relevance of the linked page to search engines.
Now, let’s explore how Python can simplify the process of finding contextual internal links on any website.
Preparing Your Python Environment
Before diving into web crawling, it’s crucial to set up your Python environment and import the necessary libraries. We’ll use libraries like requests for making HTTP requests, BeautifulSoup for parsing HTML, and openpyxl for working with Excel files. Additionally, we’ll configure the script to handle interruptions gracefully.
import os
import signal
from bs4 import BeautifulSoup
import requests
from openpyxl import Workbook
from urllib.parse import urlparse, urljoin
import urllib3
import sys
import re
Defining the Target Website
Next step is to define the website that you want to crawl. In this example, we have mentioned “https://www.xyz.in”. You need to replace this website with your own website domain.
url = “https://www.xyz.in”
main_url = url
main_domain = urlparse(main_url).netloc
Skipping Unwanted URL Patterns
Not all the links present on a website are relevant for crawling. We have defined 2 different types of skip patterns.
- Skip patterns crawl – to skip URLs from crawling which are not relevant
- Skil patterns – to skip URLs to get stored in Excel
# Pages to skip while crawling
skip_patterns_crawl = [
“/jobs/”,
# Add more URL patterns to skip here
]
# Pages to skip while storing URLs in Excel
skip_patterns = [
“page”,
“/all-articles/”,
# Add more URL patterns to skip here
]
# …
Crawling the Website
The core of our web crawling script is the crawl_website function. This function recursively navigates through the website, extracts data from HTML pages, and stores relevant information in the Excel file. It also handles interruptions.
Filtering mechanism for Contextual Links
Not all internal links are created equal. Contextual internal links are those that are relevant to the content of the page. To identify these links, you’ll need to consider following items:
- Contextual links often appear in the body of the content, so we’ll need to narrow down our search to body tag
- Exclude Navigational menu – we need to identify classes used by website and put them in exclusion list e.g. menu, navigation
- Some websites have links in footer – to handle this we need to identify footer classes and put them in exclusion list e.g. footer
- Exclude CTAs we need to exclude button class
- Exclude related blogs in blogs page, we need to find their classes and put them in exclusion list e.g. blog-overview
classes = link.get(‘class’, [])
parent_hierarchy_classes = [cls for cls in link.find_parents() for cls in cls.get(‘class’, [])]
all_classes = classes + parent_hierarchy_classes
if not any(keyword in cls for cls in all_classes for keyword in [‘menu’, ‘navigation’, ‘link-list’, ‘footer’,’button’,’blog-overview’]):
print(f”Crawling URL: {href}”)
# Check the file extension of the URL
file_extension = os.path.splitext(parsed_href.path)[-1]
if not file_extension:
ws_internal.append([href, url, anchor_text]) # Add ‘Anchor Text’
Handling Interrupts and Errors
Web crawling can be time-consuming, and interruptions or errors can occur. We’ve implemented a signal handler to save progress when the script is interrupted (e.g., with Ctrl+C). Additionally, we handle exceptions to ensure the script continues running in the face of errors.
Signal handler for interrupt signal (Ctrl+C)
def interrupt_handler(signal, frame):
# Save the Excel file
wb.save(file_path)
print(‘Excel file saved to:’, file_path)
exit(0)
Python Full Code
# DISCLAIMER: This code is provided for educational purposes and is intended for crawling and analyzing your own website only. Crawling other websites without proper authorization may violate terms of service and legal regulations. # Use this code responsibly and in compliance with applicable laws and regulations.
import os
import signal
from bs4 import BeautifulSoup
import requests
from openpyxl import Workbook
from urllib.parse import urlparse, urljoin
import urllib3
import sys
import re
# Increase the recursion limit
sys.setrecursionlimit(3000) # Set a higher recursion limit (adjust the value as needed)
# Define the website URL to crawl
url = "https://www.xyz.in"
main_url = url
# Parse the domain from the main URL
main_domain = urlparse(main_url).netloc
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# pages to skip while crawling
skip_patterns_crawl = [
"/jobs/"
# Add more URL patterns to skip here
]
# pages to skip while storing URLs in excel
skip_patterns = [
"page",
"/all-articles/",
"/press/",
"/terms-and-conditions/"
# Add more URL patterns to skip here
]
file_path = r'C:\crawler.xlsx'
# Remove the existing file if it exists
if os.path.isfile(file_path):
os.remove(file_path)
# Create a new workbook
wb = Workbook()
ws_internal = wb.active
ws_internal.title = 'Internal URLs'
# Define the headers for the Excel file
headers_internal = ['URL', 'Prev Linking URL', 'Anchor Text'] # Add 'Anchor Text'
# Write the headers to the internal worksheet
ws_internal.append(headers_internal)
# Set to store visited URLs
visited_urls = set()
counter = 0
# Signal handler for interrupt signal (Ctrl+C)
def interrupt_handler(signal, frame):
# Save the Excel file
wb.save(file_path)
print('Excel file saved to:', file_path)
exit(0)
# Register the signal handler
signal.signal(signal.SIGINT, interrupt_handler)
# Function to extract data from the website and write to Excel
def crawl_website(url, previous_url=''):
# Check if the URL has already been visited or if execution was interrupted
global counter
if url in visited_urls:
return
def should_skip(url):
for pattern in skip_patterns:
if pattern in url:
return True
return False
def should_skip_crawl(url):
for pattern in skip_patterns_crawl:
if pattern in url:
return True
return False
# Add the URL to the visited set
visited_urls.add(url)
try:
# Send a GET request to the website with verify=False for SSL certificate verification bypass
response = requests.get(url, allow_redirects=False, verify=False)
except requests.exceptions.InvalidSchema:
# Skip invalid URLs
return
# Write the data to the Excel sheet
soup = BeautifulSoup(response.content, 'html.parser')
body = soup.find('body')
if (not should_skip(url)):
if body:
# Check if the page has a body tag before trying to find links within it
for link in body.find_all('a', href=True):
href = link['href']
anchor_text = link.get_text() # Get the anchor text
if not anchor_text.strip():
continue
if href and '#' not in href and not should_skip(href):
if href.startswith('/'):
href = urljoin(main_url, href)
parsed_href = urlparse(href)
if parsed_href.netloc == main_domain:
classes = link.get('class', [])
parent_hierarchy_classes = [cls for cls in link.find_parents() for cls in cls.get('class', [])]
all_classes = classes + parent_hierarchy_classes
if not any(keyword in cls for cls in all_classes for keyword in ['menu', 'navigation', 'link-list', 'footer','button','blog-overview']):
print(f"Crawling URL: {href}")
# Check the file extension of the URL
file_extension = os.path.splitext(parsed_href.path)[-1]
if not file_extension:
ws_internal.append([href, url, anchor_text]) # Add 'Anchor Text'
counter += 1
print(f"Crawl Number: {counter}")
# Crawl the links on the page
if body:
for link in body.find_all('a', href=True):
href = link['href']
if href and '#' not in href and not should_skip_crawl(href):
if href.startswith('/'):
href = urljoin(main_url, href)
parsed_href = urlparse(href)
if parsed_href.netloc == main_domain:
#print(f"Crawling URL: {href}")
crawl_website(href, url)
try:
# Call the crawl_website function for the main URL
crawl_website(url)
except Exception as e:
print(f"An error occurred during the crawl: {str(e)}")
# Save the Excel file
wb.save(file_path)
# Print the file path
print('Excel file saved to:', file_path)
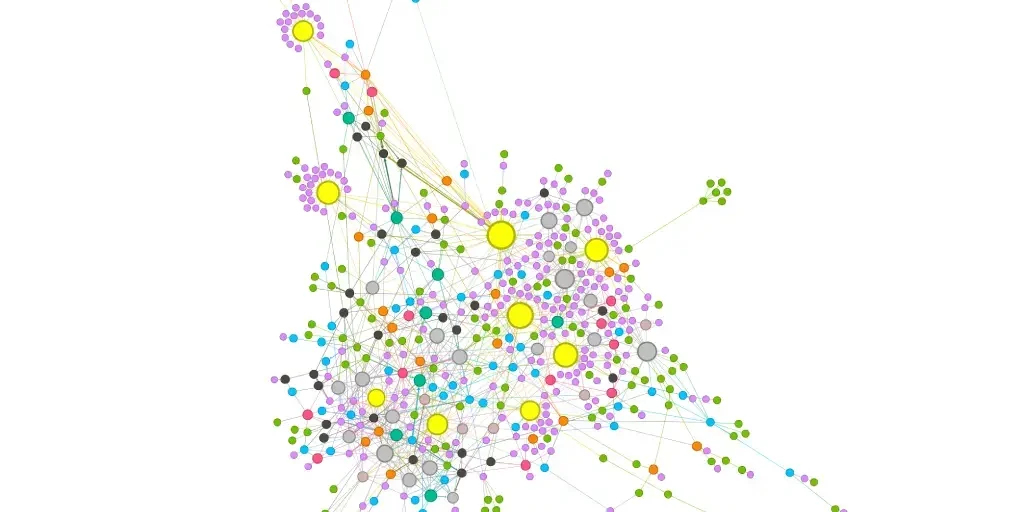
Generating Reports and Visualizations
To enhance the practicality of your analysis, you can create comprehensive reports and visualizations using freely available tools such as Gephi. In our next blog post – How to Find Existing Pillar Pages and Their Cluster Topics of Any Website, we will provide a detailed step-by-step guide that walks you through the process of generating a graph representation of a website. This visualization will include the pillar pages and cluster pages, all interconnected through nodes, providing a clear and actionable representation.
Best Practices for Internal Link Optimization
Now that you have a solid understanding of how to find and analyze contextual internal links using Python, it’s essential to know some best practices for optimizing your internal linking strategy:
Use Descriptive Anchor Text
Ensure that the anchor text you use for internal links accurately describes the linked page’s content. This helps both users and search engines understand the context.
Prioritize Relevant Links
Link to pages that are genuinely relevant to the current content. Avoid overloading pages with unnecessary internal links.
Create a Logical Structure
Organize your internal links in a way that makes sense for users. Create a hierarchy of topics and link accordingly.
Update and Maintain Links
Regularly check and update your internal links to ensure they remain relevant. Broken links can harm user experience and SEO.
Balancing SEO and User Experience
While optimizing for SEO is essential, it’s equally crucial to consider the user experience. Internal links should enhance navigation and provide value to your audience. Striking the right balance between SEO and user experience is key to a successful internal linking strategy.
Avoiding Common Mistakes
Over-Optimization: Avoid excessive internal linking, as it can be seen as spammy by search engines. Focus on quality over quantity.
Ignoring Mobile Optimization
Ensure that your internal links work well on mobile devices. Mobile-friendliness is a crucial ranking factor.
Neglecting Page Speed
Heavy use of internal links can impact page loading speed. Optimize your website for performance to improve user experience and SEO.
Conclusion
Using Python for internal link analysis is a powerful way to enhance your SEO efforts. It allows you to efficiently discover, filter, and analyze internal links on any website, helping you make data-driven decisions to optimize your internal linking strategy. By following best practices and regularly monitoring your internal links, you can improve both SEO rankings and user engagement on your website.
He has helped brands/enterprices across IT/ITeS, E-commerce, Telecommunications, and Automotive sectors enhance visibility, user experience, and conversion rates through advanced SEO strategies along with AI and python to enhance user experience, boost conversion rates, and amplify brand awareness.
Driven by a passion for innovation, he focuses on leveraging emerging technologies to revolutionize SEO and content performance.
- Top AI Marketing Tools in 2026 - December 2, 2025
- Best SEO Content Optimization Tools - November 13, 2025
- People Also Search For (PASF): The Complete 2025 Guide to Smarter SEO Optimization - November 11, 2025