Last Updated on September 19, 2025
Contents
- Setting Up Python for SEO Work
- Essential Python Libraries required
- Use Case 1: Web site Crawler
- Use Case 2: Index your website faster using google indexing API
- Use Case 3: Semantic Keyword Clustering
- Use Case 4: Check active backlinks
- Use Case 5: Build a Grammatical and Spelling Website Checker
- Use Case 6: Finding Existing Pillar Pages and Their Cluster Topics
- Use Case 7: Finding right Keywords and their Density
- Use Case 8: Find Contextual Internal Links on Website with Python
- Use Case 9: NLP Content Clustering for 1,000+ URLs
- ‘Use Case 10: Automating Keyword Research with N-Gram Analysis
- Other user cases of python for SEO
- About Python Programming Language
Python has gained significant popularity in the field of marketing due to its versatility and ease of use. With its extensive libraries and frameworks, Python, a versatile programming language offers marketers a wide range of tools to automate tasks, analyze data, and enhance marketing strategies. In this blog, we will explore various practical use cases where Python skills can be applied to create python tools to automate SEO. Each use case will be accompanied by complete Python code to help you get started. Let’s dive in!
Setting Up Python for SEO Work
Before diving into python script automation for creating SEO tools, you’ll need to set up your Python environment. There are several ways to do this, depending on your preferences and needs:
1. Local Installation
Installing Python directly on your computer is the most common method:
- Pros: Full control over your environment, works offline, faster execution
- Cons: Requires manual setup and management of packages
Steps:
- Download Python from the official website (python.org)
- Install it on your computer
- Use pip (Python’s package manager) to install necessary SEO-related libraries
Integrated Development Environments (IDEs)
As part of your local setup, you might want to use an IDE, which provides a complete coding environment with helpful features:
- Pros: All-in-one solution, code completion, debugging tools
- Cons: Can be resource-intensive, may have a learning curve
2. Cloud-Based Platforms
Cloud platforms let you code Python in your web browser:
- Pros: No installation required, accessible from any device, easy to share
- Cons: Requires internet connection, may have limitations on processing power or storage
Options:
- Google Colab: Free, integrates with Google Drive
- Kaggle Kernels: Great for data science and SEO analysis
- Replit: User-friendly interface, good for beginners
Choose the setup that best fits your working style and project needs. For beginners, a local installation or cloud-based platform is often the easiest way to start using Python for SEO tasks.
Essential Python Libraries required
Before diving into the actual code, let’s understand the common libraries that are essential for creating SEO automation scripts. These libraries help with tasks such as web crawling, parsing, reading/writing Excel files, data analysis, and more.
| S.No. | Library | Description |
| 1 | requests | Used for making HTTP requests to fetch web pages. The requests library allows you to send HTTP requests easily and handle responses efficiently, making it essential for web scraping and accessing web resources. It provides a simple and intuitive API for sending requests, handling cookies, redirections, and more. |
| 2 | Beautiful Soup (bs4) | Used for parsing HTML and XML documents. Beautiful Soup provides functions to navigate and search through the HTML/XML tree, making it easy to extract data from web pages. It’s commonly used in web scraping projects to locate and extract specific elements or data from HTML/XML documents. |
| 3 | openpyxl | Used for reading and writing Excel files. The openpyxl library allows you to manipulate Excel files programmatically, making it useful for storing and analyzing data obtained from web scraping or other sources. It provides functionality to create, read, modify, and save Excel workbooks and worksheets. |
| 4 | urllib.parse | Used for parsing URLs. This module provides functions for parsing URLs into their component parts, such as scheme, netloc, path, query parameters, etc. It’s helpful for working with URLs in web scraping and SEO automation tasks, allowing you to extract and manipulate different parts of a URL. |
| 5 | signal | Used for handling operating system signals. The signal module provides facilities to register signal handlers for specific events, such as interrupts (Ctrl+C). It’s useful for gracefully handling interruptions in long-running processes, like web crawlers or data processing scripts. |
| 6 | pandas | Used for data manipulation and analysis. pandas provides data structures (like DataFrame and Series) and functions for efficiently handling structured data. It’s commonly used for data processing and analysis tasks in SEO automation projects, allowing you to clean, transform, and analyze data. |
| 7 | sys | Used for interacting with the Python runtime environment. The sys module provides access to system-specific parameters and functions, such as setting recursion limits (sys.setrecursionlimit()). It’s useful for adjusting runtime behavior and system-level configurations, which can be beneficial in complex web scraping or data processing tasks. |
| 8 | re (Regular Expressions) | Used for pattern matching and text manipulation. The re module provides functions for working with regular expressions, allowing you to search, extract, and manipulate text based on specific patterns. It’s helpful for tasks like URL pattern matching, data extraction, and text cleaning. |
| 9 | language_tool_python | Used for grammar and spell checking. This library integrates with LanguageTool, an open-source proofreading software, to provide grammar and spell checking capabilities. It’s useful for ensuring the quality of textual content in SEO projects, such as meta descriptions, titles, and other on-page elements. |
| 10 | trafilatura | Trafilatura is a Python library designed for web scraping, specifically focused on extracting and cleaning text content from web pages, making it ideal for tasks like content extraction and text analysis in SEO projects. |
| 11 | NLTK | The Natural Language Toolkit (NLTK) is a comprehensive Python library used for natural language processing (NLP). It provides tools for text analysis, tokenization, and linguistic data processing, which are essential for understanding and optimizing textual content for SEO. |
| 12 | spaCy | spaCy is an advanced NLP library in Python known for its speed and efficiency. It offers state-of-the-art tools for tokenization, named entity recognition, and part-of-speech tagging, helping SEO professionals analyze and process large volumes of text data quickly and accurately. |
| 13 | sklearn | Scikit-learn (sklearn) is a powerful machine learning library for Python. It offers a wide range of algorithms for tasks like classification, regression, clustering, and more. With sklearn, you can build predictive models to analyze website traffic, identify keyword trends, and optimize your SEO strategy. |
By leveraging these libraries, you can create robust and efficient SEO automation scripts that can handle SEO tasks such as web crawling, data extraction, data processing, and quality assurance. However, keep in mind that some of these libraries may require additional dependencies or configurations based on your specific use case.
1. Web site Crawler
With website crawler you can find out critical errors like missing pages, broken links etc.
Python allows marketers to inspect their own website to find out web errors and overall health of website. Python’s libraries like BeautifulSoup and Scrapy make web scraping a breeze.
Full code to website crawler can be found here – crawl an entire website using python
How does it work?
- Import necessary libraries/modules including
os,signal,BeautifulSoupfrombs4,requests,openpyxl,datetime,urlparsefromurllib.parse,urllib3, andsys. A higher recursion limit is set usingsys.setrecursionlimit(). - Define the URL to crawl (
url), skip patterns (skip_patterns), and file path for the Excel workbook (file_path). - Set up the Excel workbook (
wb) usingopenpyxland an internal worksheet (ws_internal) with headers defined byheaders_internal. - Define the function
crawl_websiteto crawl the website recursively, extract data, and write it to the Excel workbook. Handle the interrupt signal (signal.SIGINT) usinginterrupt_handler. - Handle exceptions during crawling using
tryandexcept. Call thecrawl_websitefunction for the main URL (url). - Finally, save the Excel file using
wb.save(file_path).
2. Index your website faster using google indexing API
Indexing your website faster is crucial for improving its visibility on search engines and driving organic traffic. The Google Indexing API allows webmasters to notify Google about new or updated content on their site, expediting the indexing process. By using Python to interact with the API, you can automatically submit URLs for indexing as soon as they are published or modified. This not only helps search engines discover your content faster but also ensures that the latest version of your web pages appears in search results promptly.
Here is python script to implement the same – Google Indexing API with Python
How does it work?
- Imports necessary libraries/modules including
ServiceAccountCredentialsfromoauth2client.service_account,buildfromgoogleapiclient.discovery,httplib2, andopenpyxl. - Defines constants such as
EXCEL_FILE,JSON_KEY_FILE,SCOPES, andENDPOINTfor the Excel file path, JSON key file path, OAuth scopes, and Google Indexing API endpoint respectively. - Authorizes credentials using
ServiceAccountCredentials.from_json_keyfile_name()and builds a service object withbuild(). - Defines a callback function
insert_event()to handle batch HTTP request responses. - Initializes a batch HTTP request object using
service.new_batch_http_request(callback=insert_event). - Reads URLs from the Excel file specified in
EXCEL_FILEusingopenpyxl, and appends them to a listurls. - Iterates over each URL in the list
urlsand adds a URL notification request to the batch usingbatch.add().
3. Semantic Keyword Clustering
Semantic Keyword Clustering is a powerful marketing use case that Python can efficiently handle. With the vast amount of data available on the internet, marketers often struggle to organize keywords effectively for their SEO and content strategies. By utilizing Python’s Natural Language Processing (NLP) libraries, such as spaCy or others, marketers can group keywords based on their semantic meaning rather than exact match phrases. This approach enables the identification of related keywords, allowing marketers to create more comprehensive and relevant content, target a broader range of search queries, and improve their website’s overall search engine ranking.
Here is full code to Semantic Keyword Clustering with Python
How does it work?
- Imports necessary libraries/modules including
pandasaspd,spacy(for spacy model) and sentence_transformers import SentenceTransformer(for Bert and Roberts model) - Loads the appropriate model using
load() function. - Reads keywords from an Excel file located at ‘C:\keywordcluster.xlsx’ using
pd.read_excel(). - Processes keywords using model, obtaining document vectors for each keyword.
- Groups keywords by similarity, forming clusters.
- Identifies the pillar page keyword for each cluster based on maximum similarity within the cluster.
- Prints clusters along with their pillar page keywords.
- Creates and writes the DataFrame to a new sheet in the same Excel file using
pd.ExcelWriter().
4. Check active backlinks
The Backlinks Checker is another valuable use case for Python in marketing. Backlinks are essential for improving a website’s authority and search engine ranking. With Python, marketers can automate the process of checking and monitoring backlinks to their website. By leveraging Python libraries like Requests and BeautifulSoup, marketers can crawl through various web pages to identify and extract backlinks pointing to their site. Additionally, Python can analyze the quality and relevance of these backlinks, enabling marketers to assess the impact on their SEO efforts. With an automated Backlinks Checker implemented in Python, marketers can efficiently manage their link building strategies, identify potential opportunities for collaboration, and proactively address any negative backlinks that could harm their website’s reputation.
Here is full code to check existing backlinks and their quality – Dofollow or Nofollow
How does it work?
- Imports necessary libraries/modules including
pandasaspd,datefromdatetime,requests, andBeautifulSoupfrombs4. - Defines a function
get_backlink_type(url)to determine the type of backlink (dofollow or nofollow) for a given URL. - Makes a GET request to the URL, parses the HTML content using BeautifulSoup, and finds all anchor tags (
<a>). - Filters anchor tags containing the backlink URL (
backlink_url) and determines their rel attributes to identify if they are dofollow or nofollow. - Returns the type of backlink or an error message if the request fails or no backlink is found.
- Handles different scenarios for backlink types and prints corresponding messages.
- Catches
requests.exceptions.RequestExceptionand returns appropriate error messages.
5. Build a Grammatical and Spelling Website Checker
Grammar and spell check is also a very crucial component of website SEO. Google doesn’t like sites with grammatical errors. You can use python code to crawl entire website, identify grammar and spelling errors, and store the results in an Excel file. This can be a valuable tool to improve the SEO of your website.
How does it work?
- Initialization and Setup: The script sets the recursion limit, defines the target website URL, and configures URL patterns to skip during crawling. It initializes an Excel workbook to store the results and sets up a language checking tool.
- Signal Handling: A signal handler is registered to save the Excel file if the script is interrupted (e.g., via Ctrl+C).
- URL Management: Checks if a URL has already been visited or if it should be skipped based on predefined patterns.
- Domain Filtering: Ensures only internal URLs are processed.
- Content Extraction and Grammar Checking: Parses the HTML content to extract text. Uses
language_tool_pythonto check for grammar and spelling errors. Writes detailed error information to the Excel file, including the URL, previous linking URL, error details, and context. - Recursive Crawling: The function recursively crawls internal links on the target website, adhering to the same filtering and extraction process.
- Error Handling and Completion: Catches and prints errors, saves the Excel file, and confirms the file path.
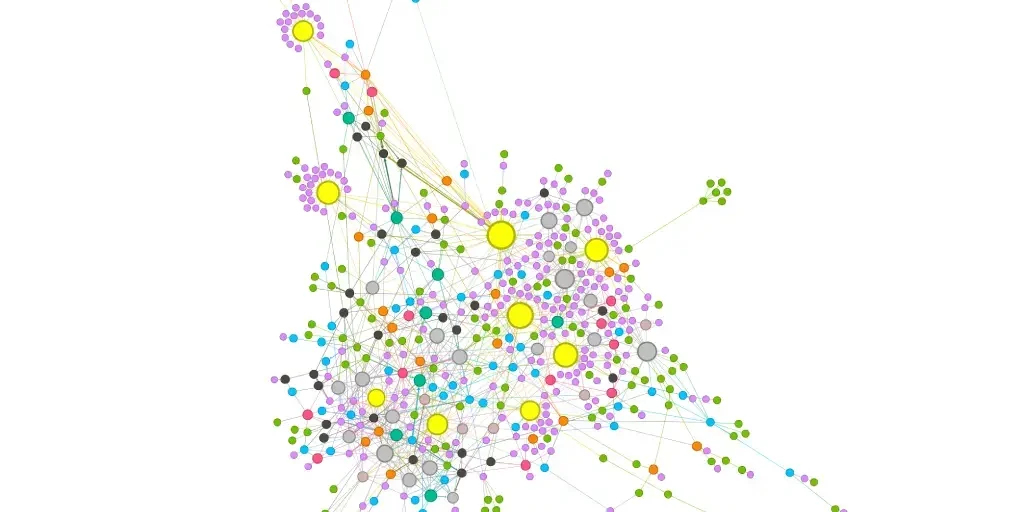
6. Finding Existing Pillar Pages and Their Cluster Topics
Understanding the structure and interconnections of a website is crucial for effective SEO, user experience, and content strategy- specially, how pillar pages are interconnected with their clusters. With the help of Python and Gephi we can visualize the architecture of websites and gain valuable insights into the relationships between pages. In this use case, we will explore we can create visual representations of complete website, providing a clear and comprehensive overview of pillar and cluster pages and how they are interconnected.
Here are step by step instructions to find Pillar pages and their Cluster topics
7. Finding right Keywords and their Density
Keywords are the building blocks of effective SEO and content marketing strategies. By performing TF-IDF (Term Frequency-Inverse Document Frequency) analysis using Python, marketers can identify the most important and relevant keywords in a collection of documents. TF-IDF assigns a weight to each term based on its frequency in a document relative to its occurrence in the entire corpus. In this use case, we will explore how Python can be employed to extract essential keywords through TF-IDF analysis, providing valuable insights for optimizing content and improving search engine rankings.
8. Find Contextual Internal Links on Website with Python
In today’s digital landscape, optimizing website content for both users and search engines is paramount. One essential aspect of this optimization is creating effective internal linking structures that enhance user experience and improve search engine rankings. Contextual internal linking plays a pivotal role in achieving these goals. Python, can be used to identify and harness the importance of contextual internal links on websites that can drive traffic, improve SEO, and ultimately enhance the overall performance of your website.
Here is full code to finding contextual Internal links on website with Python
How does it work?
- Initialization and Setup: The script sets the recursion limit, defines the target website URL, and configures URL patterns to skip during crawling and storage. It initializes an Excel workbook to store the results.
- Signal Handling: A signal handler is registered to save the Excel file if the script is interrupted (e.g., via Ctrl+C).
- URL Management: Checks if a URL has already been visited or if it should be skipped based on predefined patterns.
- Request Handling: Sends GET requests to the URLs, handling SSL certificate verification issues.
- Content Extraction: Parses the HTML content to find anchor tags (
<a>), filtering out unnecessary links (e.g., navigation, footer). - Data Storage: Writes the URL, previous linking URL, and anchor text to the Excel file.
- Recursive Crawling: The function recursively crawls internal links on the target website, adhering to the same filtering and extraction process.
9. NLP Content Clustering for 1,000+ URLs
Organizing and making sense of vast amounts of web content is crucial for businesses and researchers alike. By leveraging the power of machine learning and text analysis, we can automatically group related web pages, making it easier to navigate, analyze, and derive insights from large-scale web content.
How it works:
- Data Collection: The process starts by parsing XML sitemaps to gather a large number of URLs from target websites.
- Content Extraction: Using libraries like Trafilatura, the main text content is extracted from each webpage, removing HTML tags and boilerplate elements.
- Text Preprocessing: The extracted text undergoes cleaning and preprocessing, including lowercasing, removal of punctuation and stopwords, and tokenization.
- Vectorization: The preprocessed text is converted into numerical vectors using techniques like Count Vectorization, enabling mathematical analysis.
- Similarity Calculation: Cosine similarity is computed between the vectorized documents to measure content similarity.
- Clustering: URLs are grouped into clusters based on their content similarity, using a threshold-based approach that doesn’t require predetermining the number of clusters.
Here is python script to NLP Content Clustering for 1,000+ URLs with Python
10. Automating Keyword Research with N-Gram Analysis
By automating the process of extracting and analyzing keywords from competitors’ top-ranking content via Natural Language Processing, digital marketers can gain valuable insights to inform their SEO strategies. This Automating Keyword Research with N-Gram Analysis and NLP tutorial walks readers through the concept of N-Gram analysis, provides code snippets for implementation, and offers practical advice on applying the results to enhance content optimization and overall search engine rankings.
How it works:
- Fetch URLs: The script retrieves URLs from Google search results for a given query.
- Extract content: It crawls these URLs and extracts the text content from each webpage.
- Generate N-Grams: The text is processed to create 1-gram, 2-gram, and 3-gram keyword phrases.
- Filter and count: Stopwords are removed, and the frequency of each N-Gram is counted, distinguishing between top 3 results and positions 4-10.
- Analyze results: The script provides a ranked list of keywords and phrases, highlighting those most associated with high-ranking content.
- Apply insights: Marketers can use these results to identify primary keywords, discover related topics, find long-tail keyword opportunities, and guide content creation and optimization.
Other user cases of python for SEO
- Checking schema data
- Checking page speed
- Identifying SSL certificates
- SEO Audit/ SEO analyzer tool/ SEO technical audit
- Link validator script
- Automating redirect maps
- Writing meta descriptions in bulk
- Analyzing keywords with N-grams
- Grouping keywords into topic clusters
- Analytics python tool
For a complete SEO advanced guide you can visit our Advanced SEO section
Where to Find Python Projects
- GitHub is a fantastic resource for learning Python. Discover a vast array of open-source projects, tutorials, and code examples. From beginner-friendly guides to advanced projects, GitHub repository offers something for everyone.
- Bitbucket: A popular code hosting platform for teams, Bitbucket also hosts a vast number of open-source Python projects.
- GitLab: Similar to GitHub and Bitbucket, GitLab is a comprehensive code collaboration and management platform with a large repository of Python projects.
About Python Programming Language
| Python was developed by | Guido van Rossum |
| Python is Maintained by | Python Software Foundation |
| Python Website | www.python.org |
| Python was Created In | February 1991 |
| Python Programming Uses | Web dev, ML, automation, SEO, … |
| Python’s name origin | Monty Python’s Flying Circus |
| Python SEO usage | Automation and data processing |
Learning Python and its implementation has become an invaluable tool for marketers, offering a multitude of SEO use cases to enhance marketing efforts. By understanding SEO data, mastering technical SEO, and becoming proficient in Python programming, you can create your own DIY SEO experiments and build a powerful SEO toolkit.
He has helped brands/enterprices across IT/ITeS, E-commerce, Telecommunications, and Automotive sectors enhance visibility, user experience, and conversion rates through advanced SEO strategies along with AI and python to enhance user experience, boost conversion rates, and amplify brand awareness.
Driven by a passion for innovation, he focuses on leveraging emerging technologies to revolutionize SEO and content performance.
- Top AI Marketing Tools in 2026 - December 2, 2025
- Best SEO Content Optimization Tools - November 13, 2025
- People Also Search For (PASF): The Complete 2025 Guide to Smarter SEO Optimization - November 11, 2025